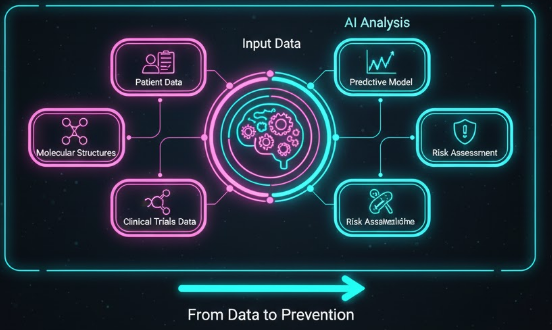
TensorFlow 2.x has revolutionized deep learning development with its intuitive Keras API, eager execution by default, and seamless deployment capabilities. Let's explore how to build production-ready neural networks.
Setting Up Your Environment
pip install tensorflow numpy pandas matplotlib
import tensorflow as tf
from tensorflow import keras
print(tf.__version__) # Should be 2.x
Building Your First Neural Network
Using the Sequential API for simple models:
model = keras.Sequential([
keras.layers.Dense(128, activation='relu', input_shape=(784,)),
keras.layers.Dropout(0.2),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
The Functional API (For Complex Architectures)
inputs = keras.Input(shape=(784,))
x = keras.layers.Dense(128, activation='relu')(inputs)
x = keras.layers.Dropout(0.2)(x)
x = keras.layers.Dense(64, activation='relu')(x)
outputs = keras.layers.Dense(10, activation='softmax')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
Training Best Practices
- Callbacks: Use EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
- Validation Split: Always monitor validation metrics
- Batch Size: Start with 32 or 64, adjust based on memory
- Learning Rate: Start with 0.001, use learning rate schedules
callbacks = [
keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True),
keras.callbacks.ModelCheckpoint('best_model.h5', save_best_only=True),
keras.callbacks.ReduceLROnPlateau(factor=0.5, patience=5)
]
history = model.fit(
X_train, y_train,
validation_split=0.2,
epochs=100,
batch_size=32,
callbacks=callbacks
)
Common Architectures
Convolutional Neural Networks (CNNs):
model = keras.Sequential([
keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
keras.layers.MaxPooling2D((2,2)),
keras.layers.Conv2D(64, (3,3), activation='relu'),
keras.layers.MaxPooling2D((2,2)),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
Recurrent Neural Networks (RNNs):
model = keras.Sequential([
keras.layers.LSTM(128, return_sequences=True, input_shape=(None, features)),
keras.layers.LSTM(64),
keras.layers.Dense(output_dim, activation='softmax')
])
Transfer Learning
Leverage pre-trained models for better performance:
base_model = keras.applications.MobileNetV2(
input_shape=(224, 224, 3),
include_top=False,
weights='imagenet'
)
base_model.trainable = False
model = keras.Sequential([
base_model,
keras.layers.GlobalAveragePooling2D(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(num_classes, activation='softmax')
])
Model Evaluation & Debugging
- Plot training history to detect overfitting
- Use confusion matrices for classification
- Visualize layer activations to understand learning
- Monitor gradient flow to prevent vanishing/exploding gradients
Deployment
# Save model
model.save('my_model.h5')
# Load model
loaded_model = keras.models.load_model('my_model.h5')
# Convert to TensorFlow Lite for mobile
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
TensorFlow 2.x makes deep learning accessible while maintaining the power needed for cutting-edge research and production systems!
.png)

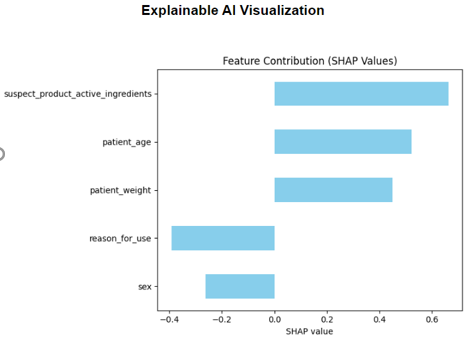

.jpg)
.png)